Agenta
Agenta is an open-source LLMOps platform that centralizes prompt management, evaluation, and observability for reliable.
tool Details
Explore More
Alternatives
About Agenta
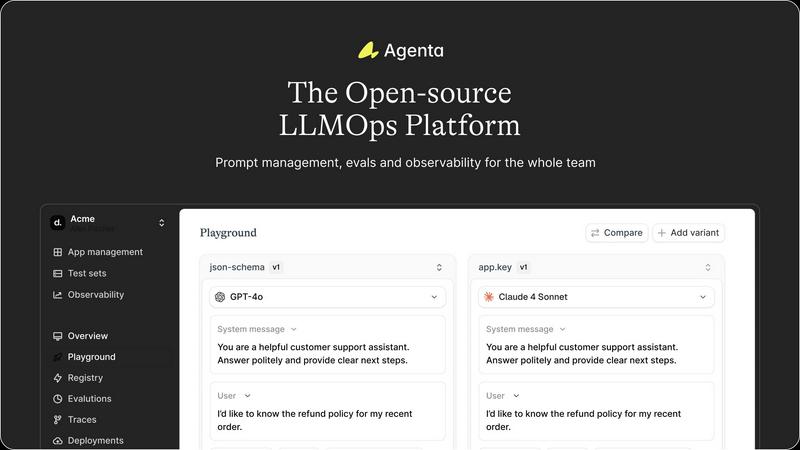
Agenta is an open-source LLMOps platform specifically designed to address the challenges faced by AI development teams in building reliable Large Language Model (LLM) applications. It provides the necessary infrastructure to facilitate the entire lifecycle of LLM development, from inception to deployment. By centralizing key processes such as prompt management, evaluation, and observability into a single, collaborative environment, Agenta helps teams mitigate the unpredictability and fragmented workflows that often plague LLM projects. It is tailored for cross-functional teams, including developers, product managers, and subject matter experts, enabling them to transition from ad-hoc prompt management and "vibe testing" to a structured, evidence-driven approach. The platform's primary value proposition lies in its integration of three critical pillars of LLMOps: a unified experimentation playground, systematic automated evaluation, and comprehensive production observability. Agenta serves as the single source of truth for prompts, tests, and traces, allowing teams to version control experiments, validate changes, and debug issues efficiently using real production data. This significantly reduces time-to-production, empowering teams to deliver robust AI agents swiftly.
Features
Unified Experimentation Playground
Agenta offers a unified playground that allows teams to iterate on prompts collaboratively. Users can compare different prompts and models side-by-side, ensuring that all team members are aligned in their experimentation efforts. This feature eliminates the chaos of scattered experiments, providing a structured environment for innovation.
Systematic Automated Evaluation
With Agenta, teams can replace guesswork with a systematic evaluation process. Automated evaluations enable users to run experiments, track results, and validate changes in an organized manner. This feature also allows integration with various evaluators, including LLM-as-a-judge, ensuring flexibility in evaluating LLM performance.
Comprehensive Production Observability
Agenta provides real-time observability for production systems, allowing teams to monitor performance and detect regressions. By tracing every request, users can pinpoint failure points with precision. This feature enhances debugging capabilities, enabling teams to swiftly identify and resolve issues.
Collaborative Workflow Integration
The platform fosters collaboration among product managers, developers, and domain experts by providing a user-friendly interface for prompt editing and experimentation. This feature empowers all team members to contribute to the evaluation process and compare experiments without needing extensive technical skills, promoting a more integrated workflow.
Use Cases
Collaborative LLM Development
Agenta is ideal for teams engaged in collaborative LLM development. By centralizing prompt management and evaluation, it allows developers, product managers, and domain experts to work together seamlessly, enhancing productivity and reducing bottlenecks.
Automated Testing and Validation
Teams can leverage Agenta to automate the testing and validation of their LLM applications. By systematically evaluating changes and tracking results, organizations can ensure that their models perform as expected, leading to higher reliability in production environments.
Debugging and Trace Analysis
Agenta's comprehensive observability features enable teams to conduct in-depth debugging and trace analysis. By following each request and annotating traces, users can gather valuable insights into system performance and user feedback, facilitating continuous improvement.
Rapid Iteration for Product Launches
The platform supports rapid iteration cycles, making it suitable for organizations looking to fast-track their LLM applications to production. By utilizing Agenta's unified experimentation playground, teams can validate their models more quickly, ensuring timely launches without sacrificing quality.
Frequently Asked Questions
What is LLMOps?
LLMOps refers to a set of best practices and methodologies designed to manage the lifecycle of Large Language Models. It encompasses processes such as prompt management, evaluation, deployment, and monitoring to ensure the reliability and effectiveness of LLM applications.
How does Agenta support collaboration among teams?
Agenta enhances collaboration by providing a unified platform where developers, product managers, and domain experts can work together on prompt management, evaluations, and debugging. This integration fosters communication and aligns efforts across different roles.
Can Agenta integrate with existing AI frameworks?
Yes, Agenta is designed to seamlessly integrate with popular AI frameworks and models, including LangChain, LlamaIndex, and OpenAI. This flexibility allows teams to utilize their preferred tools without being locked into a specific vendor.
Is Agenta suitable for both small and large teams?
Absolutely. Agenta is designed to accommodate teams of various sizes, from small startups to large enterprises. Its collaborative features and structured processes make it adaptable to different workflows and team dynamics.
Similar to Agenta
JustLaunched
The launch platform for indie makers — schedule your launch, get in front of buyers, and blast across directories.

EasyDoFollow
EasyDoFollow simplifies backlink building by allowing users to list their site and obtain verified dofollow links for enhanced SEO exposure.
JustHunt
JustHunt is the premier startup launchpad for gaining visibility, boosting domain ratings, and receiving valuable community feedback.