Hush Touch | Voice-to-Text for MacOS vs ltx2.site
Side-by-side comparison to help you choose the right tool.
Hush Touch | Voice-to-Text for MacOS
Hush Touch offers offline voice-to-text dictation for Mac, learning your vocabulary with a one-time $20 license.
Last updated: February 26, 2026
ltx2.site
LTX-2 is an open-source AI that generates synchronized 4K video and audio locally in one step.
Last updated: February 28, 2026
Visual Comparison
Hush Touch | Voice-to-Text for MacOS
ltx2.site
Feature Comparison
Hush Touch | Voice-to-Text for MacOS
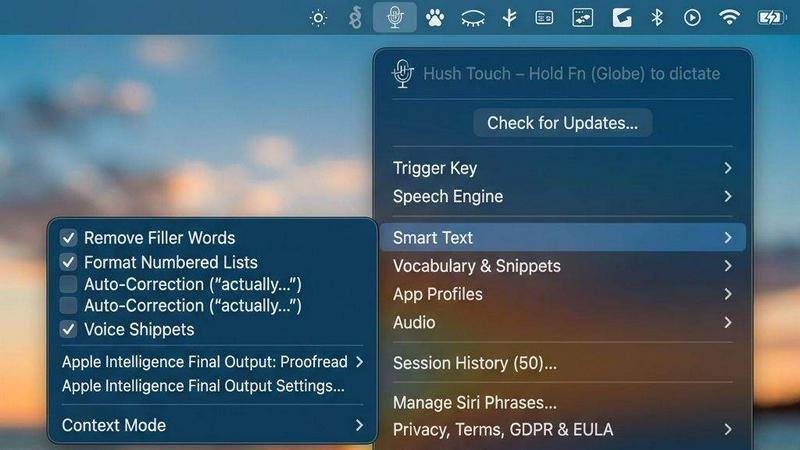
Dual-Engine Recognition
Hush Touch utilizes a sophisticated dual-engine recognition system that combines the capabilities of DictationTranscriber and SFSpeechRecognizer. The former enhances natural flow and punctuation, while the latter boosts custom vocabulary recognition. This integration results in cleaner and more accurate transcriptions tailored to your specific needs.
Custom Vocabulary
The application allows users to store up to 500 custom terms, automatically learning from corrections made during dictation. Whether you frequently use technical jargon, brand names, or specialized medical terms, Hush Touch adapts to your unique vocabulary, ensuring that your dictations reflect your language accurately.
Smart Text Processing
Hush Touch features advanced smart text processing capabilities that remove filler words and auto-correct common misinterpretations. Additionally, it can format numbered lists and recognize voice snippets for frequently used phrases, all executed in real-time without cloud dependence, ensuring a smooth dictation experience.
Context Modes & Hands-Free Operation
With multiple context modes including General, Email, Code, and Notes, Hush Touch allows users to switch seamlessly based on their dictation needs. The hands-free operation, activated via Siri or hotkeys, enables users to dictate effortlessly, with automatic text insertion after a brief pause, enhancing productivity and workflow.
ltx2.site
Unified Audio-Video Generation
LTX-2's core capability is its one-shot generation of synchronized video and audio within a single diffusion process. This eliminates the need for separate audio dubbing, post-production compositing, and tedious timeline alignment. The model is trained to understand physical correspondences, ensuring character lip movements align with speech, actions like door openings are accompanied by matching sound effects, and background music rhythm coordinates with on-screen motion. This integrated approach delivers a complete, coherent audiovisual clip directly from the generation.
Professional 4K Resolution & High Frame Rate
The model is architected to support output at professional cinematic standards, specifically up to 4096x2160 (4K) resolution and approximately 50 frames per second. This high-fidelity output is sufficient for short films and commercial-grade content, providing outstanding detail and lighting performance. The native high-quality generation means the output can be used directly in professional editing pipelines without requiring additional upscaling or frame interpolation steps, a significant advantage among open-source models.
Local Deployment on Consumer GPUs
A major technical advantage of LTX-2 is its deep optimization for local deployment on mainstream NVIDIA consumer graphics cards with high VRAM. The model's architecture offers inference efficiency several times higher than previous generations and reduces computational cost by approximately 50%. With support for low-precision weights (NVFP4/NVFP8), generating 4K video locally becomes feasible, granting users full data privacy, workflow control, and freedom from cloud service dependencies and recurring subscription fees.
Native ComfyUI Integration & Flexible Control
LTX-2 offers advanced users a highly flexible and powerful workflow through its native integration with ComfyUI, a node-based visual programming interface. This allows for intricate pipeline building, customization, and experimentation. The model supports multiple control methods including text prompts, image inputs, and sketches, and provides configurable quality and speed modes (Fast, Pro, Ultra) to allow users to perfectly balance generation quality against processing time for their specific project needs.
Use Cases
Hush Touch | Voice-to-Text for MacOS
Professional Communication
Hush Touch is perfect for professionals such as business executives and administrative staff who need to draft emails and reports quickly. The natural dictation flow allows for efficient communication without the hassle of manual typing.
Medical Documentation
Healthcare professionals can leverage Hush Touch to dictate medical notes swiftly. The app's ability to recognize medical terminology ensures that critical information is recorded accurately, saving time and reducing errors in patient records.
Creative Writing
Writers and content creators can utilize Hush Touch to brainstorm ideas and draft articles hands-free. The application's smart text processing and vocabulary learning capabilities help maintain the clarity and tone of creative pieces.
Coding and Technical Documentation
Software developers and technical writers benefit from Hush Touch's context modes and custom vocabulary features. The app can effectively transcribe coding commands and technical documentation, streamlining the development process and reducing the cognitive load.
ltx2.site
Prototyping for Film and Animation
Independent filmmakers and animation studios can use LTX-2 to rapidly prototype scenes, generate concept clips, and visualize storyboards with synchronized sound. The ability to produce up to 20 seconds of coherent, high-frame-rate 4K video with matching audio allows for the creation of compelling pitch materials and pre-visualization assets without the massive time and resource investment of traditional production methods, accelerating the creative development cycle.
AI Research and Model Development
AI researchers and developers working on multimodal systems can utilize the open-source LTX-2 model as a state-of-the-art baseline or a component for further experimentation. Its publicly available architecture and code allow for deep study into joint audio-video diffusion processes, fine-tuning on custom datasets, and the development of new control mechanisms or extensions, pushing forward the entire field of generative multimedia AI.
Dynamic Content for Social Media & Marketing
Digital marketers and social media content creators can leverage LTX-2 to produce unique, eye-catching short-form video content with perfect audio sync. This is ideal for creating engaging advertisements, product showcases, or branded storytelling clips where high production value is key. The local operation ensures brand assets and prompts remain confidential, and the speed enables rapid iteration on content ideas.
Game Development and Interactive Media
Game developers can integrate LTX-2 into their workflow to dynamically generate in-game cutscenes, character dialogue sequences, or environmental ambiance videos with matching sound effects. The model's ability to sync actions with sounds (like footsteps or door creaks) and dialogue with lip movements makes it a powerful tool for creating immersive, responsive narrative elements, especially for indie developers with limited voice-acting and animation budgets.
Overview
About Hush Touch | Voice-to-Text for MacOS
Hush Touch is an innovative voice-to-text application specifically designed for macOS users who seek a fast, natural, and secure dictation experience. Unlike traditional dictation tools that rely heavily on cloud processing, Hush Touch operates entirely on-device, ensuring that your data and voice recordings remain private. By leveraging two advanced Apple transcription engines along with an Apple Intelligence final pass, Hush Touch produces highly accurate text outputs, adapting to your unique vocabulary and speech patterns over time. This lightweight application, with a mere 5.5 MB footprint, integrates seamlessly into your daily writing tasks—be it drafting emails, writing notes, or creating documents—allowing you to dictate hands-free. With a simple activation via hotkeys or Siri, Hush Touch empowers users to communicate effectively and efficiently, making it an invaluable tool for professionals across various fields.
About ltx2.site
LTX-2, accessible via ltx2.site, is a groundbreaking open-source multimodal AI model developed by Lightricks, representing a significant leap forward in synchronized audio-video generation. This next-generation technology is engineered to produce high-quality, cinematic video clips complete with perfectly synchronized audio in a single, unified generation process. It is specifically designed for AI researchers, developers, digital artists, and professional content creators who require professional-grade output without the constraints of cloud-based subscriptions or proprietary software. The core value proposition of LTX-2 lies in its ability to generate up to 20 seconds of coherent 4K resolution video at approximately 50 frames per second, with audio elements such as dialogue, sound effects, and background music aligned precisely with on-screen actions. A key differentiator is its support for local deployment on consumer-grade NVIDIA GPUs, granting users full control over their workflow, data, and computational resources. Furthermore, its native integration with ComfyUI provides a flexible and powerful node-based interface for advanced customization and pipeline building, making it an indispensable tool for anyone pushing the boundaries of AI-generated multimedia and seeking a viable, high-quality open-source alternative.
Frequently Asked Questions
Hush Touch | Voice-to-Text for MacOS FAQ
Is Hush Touch compatible with all MacOS versions?
Hush Touch is designed to work seamlessly with the latest versions of macOS. However, it is advisable to check the system requirements on the official website for compatibility with your specific version.
How does Hush Touch ensure my privacy?
Hush Touch processes all voice data entirely on-device without using cloud services. This means that your voice recordings and transcriptions are never stored or transmitted to external servers, ensuring maximum privacy and data security.
Can I customize the activation commands for dictation?
Yes, Hush Touch allows users to set customizable command phrases for sending messages or initiating dictation, providing a personalized experience that fits individual workflows.
What is the trial period for Hush Touch?
Hush Touch offers a 7-day free trial with no credit card required. Users can experience the full functionality of the app during this period to evaluate its effectiveness in meeting their dictation needs.
ltx2.site FAQ
What hardware is required to run LTX-2 locally?
LTX-2 is optimized for local deployment on consumer-grade NVIDIA GPUs. The primary requirement is a graphics card with sufficient VRAM (Video RAM). For generating high-quality 4K video, a high-VRAM GPU is recommended. The model's efficiency improvements and support for low-precision weights (like NVFP4/NVFP8) make it feasible to run on capable consumer hardware, significantly reducing the barrier to entry for professional-grade local audio-video generation compared to previous models.
How does LTX-2 achieve synchronization between audio and video?
LTX-2 uses a multimodal diffusion architecture that jointly models three dimensions: temporal (video motion between frames), spatial (visual content per frame), and acoustic (audio waveforms). During its training on vast datasets, the model learns the physical and semantic correspondences between actions and sounds. This allows it to generate, in a single cohesive process, video where elements like lip movements are temporally aligned with generated speech waveforms, and on-screen actions are paired with appropriate sound effects.
What is the maximum output length and quality?
A single generation with LTX-2 can produce up to approximately 20 seconds of continuous, coherent audio-video content. In terms of quality, the model officially supports output resolutions up to 4096x2160 (4K) and frame rates around 50 FPS. This emphasis on coherence reduces visual flicker and structural collapse across frames, making the output suitable for narrative scenes and camera movements, rather than just short, disjointed animated clips.
Is LTX-2 completely free to use?
Yes, LTX-2 is an open-source project. The model weights, code, and architecture are publicly available, typically through its GitHub repository. This means there are no licensing fees or subscription costs to use the core technology. The only potential costs are the computational resources required to run it, namely the electricity and hardware (GPU), which you own and control when running the model locally on your own machine.
Alternatives
Hush Touch | Voice-to-Text for MacOS Alternatives
Hush Touch | Voice-to-Text for MacOS is a specialized dictation application designed for seamless offline voice-to-text conversion on macOS devices. It utilizes dual Apple transcription engines and an Apple Intelligence final pass to ensure high accuracy and fluidity in transcription. This product falls under the AI Assistants category, catering to users seeking efficient and private dictation solutions without reliance on cloud services. Users may seek alternatives to Hush Touch for various reasons, including pricing concerns, differing feature sets, and specific platform requirements. When looking for a suitable alternative, it is essential to consider factors such as offline capability, transcription accuracy, ease of use, and any unique features that may enhance the dictation experience. Evaluating these aspects will help users find a voice-to-text solution that best fits their individual needs and workflows.
ltx2.site Alternatives
LTX-2, accessible via ltx2.site, is an open-source multimodal AI model for synchronized audio-video generation. It represents a significant advancement in the AI video creation category, producing high-quality 4K clips with aligned audio in a single, local process. Users may seek alternatives for various reasons, including different pricing models, the need for cloud-based accessibility, specific feature sets like longer generation times or different artistic styles, or simpler user interfaces that do not require technical deployment. When evaluating alternatives, key considerations include the core technology (text-to-video, image-to-video), output quality (resolution, frame rate), audio synchronization capabilities, deployment method (cloud vs. local), cost structure, and the required level of technical expertise for operation and customization.