Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right tool.
Agenta is an open-source LLMOps platform that centralizes prompt management, evaluation, and observability for reliable.
Last updated: March 1, 2026
OpenMark AI benchmarks over 100 LLMs on your specific tasks, delivering insights on cost, speed, quality, and stability in minutes.
Last updated: March 26, 2026
Visual Comparison
Agenta
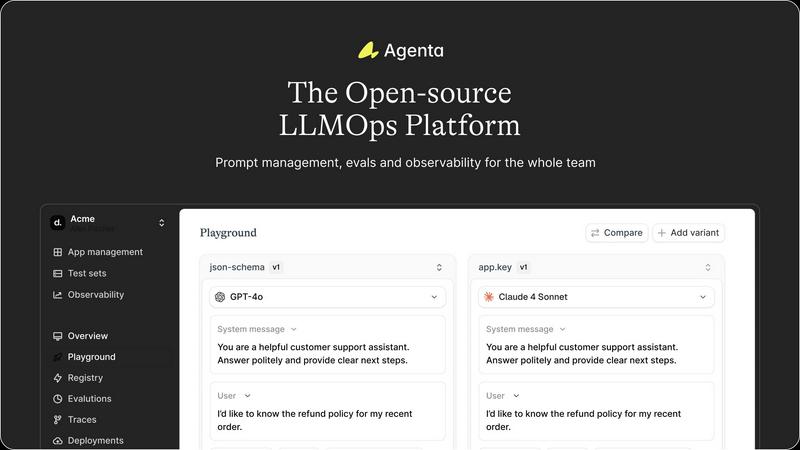
OpenMark AI

Feature Comparison
Agenta
Unified Experimentation Playground
Agenta offers a unified playground that allows teams to iterate on prompts collaboratively. Users can compare different prompts and models side-by-side, ensuring that all team members are aligned in their experimentation efforts. This feature eliminates the chaos of scattered experiments, providing a structured environment for innovation.
Systematic Automated Evaluation
With Agenta, teams can replace guesswork with a systematic evaluation process. Automated evaluations enable users to run experiments, track results, and validate changes in an organized manner. This feature also allows integration with various evaluators, including LLM-as-a-judge, ensuring flexibility in evaluating LLM performance.
Comprehensive Production Observability
Agenta provides real-time observability for production systems, allowing teams to monitor performance and detect regressions. By tracing every request, users can pinpoint failure points with precision. This feature enhances debugging capabilities, enabling teams to swiftly identify and resolve issues.
Collaborative Workflow Integration
The platform fosters collaboration among product managers, developers, and domain experts by providing a user-friendly interface for prompt editing and experimentation. This feature empowers all team members to contribute to the evaluation process and compare experiments without needing extensive technical skills, promoting a more integrated workflow.
OpenMark AI
Comprehensive Benchmarking
OpenMark AI allows users to benchmark over 100 AI models simultaneously against a variety of tasks. This feature enables teams to thoroughly analyze which model performs best for specific workflows, thereby facilitating informed decision-making.
Real-Time Cost Analysis
With OpenMark AI, users can compare the actual costs associated with API calls across different models. This feature provides transparency regarding expenses, ensuring that teams are well-aware of the financial implications of their model choices.
Consistency Checks
The platform offers the ability to evaluate the consistency of model outputs through repeat testing. Users can run the same task multiple times and verify whether results remain stable, which is crucial for applications requiring reliability.
User-Friendly Interface
OpenMark AI features an intuitive interface that requires no coding or API setup. Users can easily describe their tasks and manage benchmarks without extensive technical knowledge, making it accessible for a broad range of developers and teams.
Use Cases
Agenta
Collaborative LLM Development
Agenta is ideal for teams engaged in collaborative LLM development. By centralizing prompt management and evaluation, it allows developers, product managers, and domain experts to work together seamlessly, enhancing productivity and reducing bottlenecks.
Automated Testing and Validation
Teams can leverage Agenta to automate the testing and validation of their LLM applications. By systematically evaluating changes and tracking results, organizations can ensure that their models perform as expected, leading to higher reliability in production environments.
Debugging and Trace Analysis
Agenta's comprehensive observability features enable teams to conduct in-depth debugging and trace analysis. By following each request and annotating traces, users can gather valuable insights into system performance and user feedback, facilitating continuous improvement.
Rapid Iteration for Product Launches
The platform supports rapid iteration cycles, making it suitable for organizations looking to fast-track their LLM applications to production. By utilizing Agenta's unified experimentation playground, teams can validate their models more quickly, ensuring timely launches without sacrificing quality.
OpenMark AI
Model Selection for AI Features
Development teams can leverage OpenMark AI to identify which AI model best suits their specific use case before implementation. This ensures that the chosen model aligns with project requirements and performance expectations.
Pre-Deployment Validation
Prior to launching AI-driven features, product managers can utilize OpenMark AI to validate model performance. This step helps in mitigating risks associated with model deployment by ensuring that the selected model meets quality benchmarks.
Cost Optimization in AI Projects
Organizations can employ OpenMark AI to conduct cost-effectiveness analyses, comparing the quality of outputs relative to their costs. This strategic approach aids in maximizing return on investment for AI initiatives.
Research and Development
Research teams can utilize OpenMark AI to benchmark models for various tasks such as classification, translation, and data extraction. This capability supports the development of innovative AI solutions by identifying effective models for specific research objectives.
Overview
About Agenta
Agenta is an open-source LLMOps platform specifically designed to address the challenges faced by AI development teams in building reliable Large Language Model (LLM) applications. It provides the necessary infrastructure to facilitate the entire lifecycle of LLM development, from inception to deployment. By centralizing key processes such as prompt management, evaluation, and observability into a single, collaborative environment, Agenta helps teams mitigate the unpredictability and fragmented workflows that often plague LLM projects. It is tailored for cross-functional teams, including developers, product managers, and subject matter experts, enabling them to transition from ad-hoc prompt management and "vibe testing" to a structured, evidence-driven approach. The platform's primary value proposition lies in its integration of three critical pillars of LLMOps: a unified experimentation playground, systematic automated evaluation, and comprehensive production observability. Agenta serves as the single source of truth for prompts, tests, and traces, allowing teams to version control experiments, validate changes, and debug issues efficiently using real production data. This significantly reduces time-to-production, empowering teams to deliver robust AI agents swiftly.
About OpenMark AI
OpenMark AI is a sophisticated web application designed specifically for task-level benchmarking of large language models (LLMs). It empowers developers and product teams to articulate their testing requirements in plain language, allowing them to conduct comparative tests across multiple AI models in a single session. By evaluating cost per request, latency, scored quality, and stability through repeat runs, OpenMark AI delivers insights into model variance rather than relying on potentially misleading single outputs. This tool is particularly valuable for teams seeking to validate or select the right model before deploying AI features. With hosted benchmarking that utilizes credits, users can bypass the complexities of configuring separate API keys for OpenAI, Anthropic, or Google. OpenMark AI guarantees side-by-side results derived from real API calls, ensuring accurate comparisons that reflect true performance metrics rather than cached data. This focus on cost efficiency—where quality is assessed in relation to expenditure—makes OpenMark AI an essential tool for those prioritizing functional effectiveness over mere token cost.
Frequently Asked Questions
Agenta FAQ
What is LLMOps?
LLMOps refers to a set of best practices and methodologies designed to manage the lifecycle of Large Language Models. It encompasses processes such as prompt management, evaluation, deployment, and monitoring to ensure the reliability and effectiveness of LLM applications.
How does Agenta support collaboration among teams?
Agenta enhances collaboration by providing a unified platform where developers, product managers, and domain experts can work together on prompt management, evaluations, and debugging. This integration fosters communication and aligns efforts across different roles.
Can Agenta integrate with existing AI frameworks?
Yes, Agenta is designed to seamlessly integrate with popular AI frameworks and models, including LangChain, LlamaIndex, and OpenAI. This flexibility allows teams to utilize their preferred tools without being locked into a specific vendor.
Is Agenta suitable for both small and large teams?
Absolutely. Agenta is designed to accommodate teams of various sizes, from small startups to large enterprises. Its collaborative features and structured processes make it adaptable to different workflows and team dynamics.
OpenMark AI FAQ
What types of models can I benchmark with OpenMark AI?
OpenMark AI supports a diverse catalog of over 100 AI models, including those from major providers like OpenAI, Anthropic, and Google. This extensive selection allows for comprehensive comparisons across various tasks and requirements.
How does the credit system work for hosted benchmarking?
The hosted benchmarking feature operates on a credit system, allowing users to run comparisons without needing to configure separate API keys for each model. Users purchase credits to access benchmarking sessions, simplifying the testing process.
Can I save my benchmarking tasks in OpenMark AI?
Yes, OpenMark AI allows users to save their benchmarking tasks, enabling easy access and management of ongoing analyses. This feature supports efficiency and helps teams track their testing history and results.
Is there a free trial available for OpenMark AI?
OpenMark AI offers users 50 free credits upon signing up, allowing new users to explore the platform and conduct initial benchmarks without any financial commitment. This trial helps users understand the value of the tool before purchasing additional credits.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform designed for the development, evaluation, and debugging of reliable Large Language Model applications. It serves as a comprehensive solution for AI development teams, addressing the inherent challenges of unpredictability and fragmented workflows in LLM development by providing a unified collaborative environment. Users often seek alternatives to Agenta due to various reasons, including pricing structures, specific feature sets, or unique platform needs that may not be fully met by Agenta. When evaluating alternatives, it is essential to consider factors such as the ease of integration with existing workflows, the robustness of the evaluation framework, and the level of support for collaboration among cross-functional teams.
OpenMark AI Alternatives
OpenMark AI is a powerful web application designed for task-level benchmarking of over 100 large language models (LLMs). This tool enables developers and product teams to assess various models based on critical metrics such as cost, speed, quality, and stability, allowing for informed decisions prior to deploying AI features. Users typically seek alternatives to OpenMark AI due to factors like pricing, specific feature requirements, or compatibility with their existing platforms. When exploring alternatives, it is essential to consider the range of models supported, the granularity of benchmarking capabilities, ease of use, and overall cost efficiency. Additionally, users should assess if the alternative can provide consistent results across multiple runs, as well as the flexibility offered in terms of API integration and usability within their development environment.