Crawlkit
CrawlKit provides a developer-friendly API for seamless web scraping and data extraction from any site or platform.

About Crawlkit
Crawlkit is a powerful web data extraction platform meticulously designed for developers, data engineers, and data science teams seeking to streamline their data collection processes. It offers a comprehensive, scalable API that allows users to programmatically access and extract data from any website, effectively removing the need for complex in-house scraping infrastructures. Crawlkit addresses the modern challenges of web scraping, such as dealing with JavaScript-rendered single-page applications (SPAs), navigating aggressive anti-bot protections like Cloudflare and PerimeterX, and overcoming IP rate limiting and CAPTCHA challenges. By managing intricate tasks like proxy rotation, headless browser management, automatic retries, and session handling, Crawlkit empowers users to concentrate on data consumption and analysis. Its primary value proposition lies in delivering reliable, high-success-rate data extraction through a straightforward REST API interface, supporting various data extraction modalities including fetching raw HTML, running web searches, capturing full-page visual snapshots, and extracting structured data from professional networks. Accessible via developer-friendly SDKs for Node.js, Python, Go, and more, Crawlkit simplifies the data extraction process across multiple platforms, making it an indispensable tool for any data-driven organization.
Features
Unified API for Diverse Data Sources
Crawlkit consolidates various data extraction capabilities within a single API, enabling users to retrieve structured data from multiple sources such as LinkedIn, Instagram, and app stores with just one API call. This unified approach eliminates the hassle of managing multiple tools for different platforms.
Advanced Anti-Bot Bypassing
Crawlkit is engineered to handle sophisticated anti-bot measures, ensuring reliable data extraction even from sites protected by technologies like Cloudflare and PerimeterX. This feature allows users to access critical data without getting blocked or interrupted by security protocols.
Comprehensive Data Extraction Capabilities
Users can extract a wide range of data types, including raw HTML, structured data from professional networks, and even visual snapshots of web pages. This versatility supports various data needs, from simple web scraping to complex data analysis tasks, making Crawlkit suitable for various applications.
Flexible, Transparent Pricing Model
Crawlkit employs a credit-based pricing system that ensures users only pay for what they use, with no hidden fees or minimum commitments. This transparent pricing approach allows for scaling as needed, with credits that never expire, ensuring users can manage costs effectively while maximizing their data extraction capabilities.
Use Cases
CRM Enrichment
Crawlkit can enrich customer relationship management systems by automatically pulling essential LinkedIn profile data such as job titles, company information, and contact details for leads. This automation streamlines the sales process and enhances lead quality.
Social Media Insights
Businesses can utilize Crawlkit for tracking competitor growth on platforms like Instagram. By monitoring follower counts, engagement metrics, and post performance over time, organizations gain valuable insights into social media strategies and trends.
App Review Analysis
Crawlkit enables teams to analyze app reviews from various app stores, helping organizations understand user feedback and sentiment. By aggregating reviews, companies can make data-driven decisions to improve their applications and user experience.
Market Research and Competitive Intelligence
Crawlkit is instrumental in gathering data for market research and competitive intelligence. By extracting information from diverse sources, businesses can identify market trends, analyze competitor strategies, and make informed decisions based on comprehensive data.
Frequently Asked Questions
What types of data can I extract using Crawlkit?
Crawlkit allows users to extract a variety of data types, including structured data from social networks, app stores, and web pages, as well as raw HTML and visual snapshots. This flexibility supports diverse data collection needs.
How does Crawlkit handle anti-bot protections?
Crawlkit is specifically designed to navigate and bypass advanced anti-bot measures, such as CAPTCHAs and IP rate limiting. This capability ensures reliable data extraction without being blocked by security protocols.
Is there a limit on the number of API calls I can make?
Crawlkit operates on a credit-based system, allowing users to make API calls without imposed rate limits. Users can buy additional credits as needed, providing the flexibility to scale their data extraction efforts without restrictions.
What programming languages does Crawlkit support?
Crawlkit offers SDKs for multiple programming languages, including Node.js, Python, and Go, facilitating easy integration into various development environments. This support ensures developers can efficiently utilize the platform within their preferred tech stack.
Similar to Crawlkit
InContekst
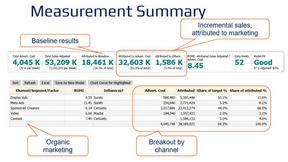
Decision support framework for high consideration businesses with mix of online and offline channels, content-rich sites, and long customer journeys.
EnsembleData
EnsembleData provides real-time, scalable APIs for extracting posts, profiles, comments, and analytics from social media platforms.

Shadcn Examples
Shadcn Examples offers comprehensive React and Tailwind UI kits with reusable components for building modern web applications efficiently.
Subiq
Subiq simplifies SaaS subscription management for small teams by tracking tools, controlling costs, and preventing unused renewals.
Flyback.ai
Flyback.ai uses AI to score luxury watch listings against verified sold data, surfacing real deals with fair value estimates and personalized wrist.