Tuning Engines
Tuning Engines is a governed universal runtime that unifies model inference, tuning, and evaluations through one API with transparent cost pricing.
tool Details
Explore More
Alternatives
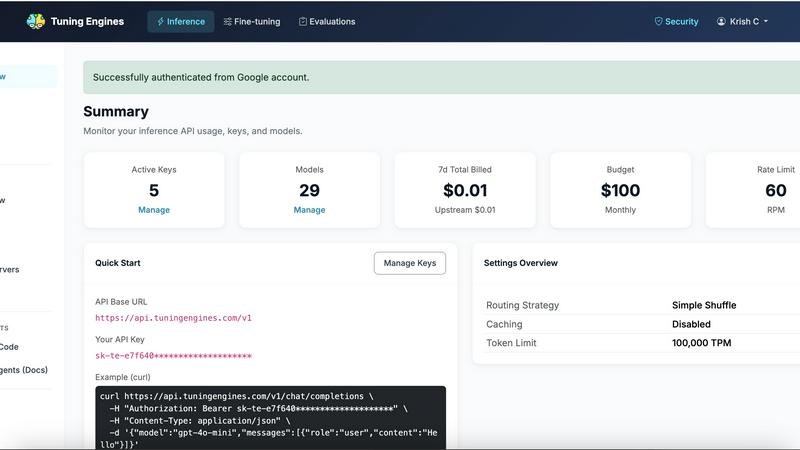
About Tuning Engines
Tuning Engines, by CerebrixOS, is a unified AI control and governance layer designed for teams building production intelligence across models, agents, tools, and fine-tuned systems. It functions as a comprehensive platform that consolidates the full AI lifecycle into a single governed environment, addressing the critical need for security, observability, cost management, and extensibility in production AI deployments. The platform brings together inference, model routing, fallback policies, fine-tuning jobs, datasets, evaluations, model imports and exports, custom models, agents, MCP servers, reusable skills, guardrails, AGT YAML policies, data capture, runtime traces, usage analytics, API keys, billing, team roles, and integrations. Developers benefit from OpenAI-compatible APIs, Anthropic-compatible routes, CLI workflows, MCP access, coding-agent integrations, and resource catalogs for models, agents, tools, and skills. The platform connects major AI development tools including Claude Code, OpenCode, Aider, Cline, Roo, Continue.dev, Cursor, VS Code, and Windsurf through a single governed access point. Administrators gain production-grade controls such as role-based access, per-key budgets, rate limits, routing profiles, fallback rules, guardrails, policy-as-code, credential sources, auditability, usage traces, billing controls, tenant isolation, and team management. A key differentiator is the infrastructure cost model: compute costs are passed through at-cost with zero markup, meaning organizations only pay for platform support and upkeep. The platform is backed by Google Cloud for Startups, NVIDIA Inception, Rogers Cybercatalyst, ElevenLabs Grants, AWS Activate, and BDC Capital, and serves as a universal intelligence runtime for secure, governed, and optimized AI interactions.
Features
Unified Inference Engine
Tuning Engines provides a single OpenAI-compatible endpoint that serves as a drop-in replacement for existing SDKs. Developers can keep their current codebase and simply swap the base URL to access over 100 models including open-weight models, commercial frontier models, and custom fine-tuned variants. The endpoint supports streaming, structured output, and all standard chat completion parameters, eliminating the need for code rewrites or learning new client libraries. Every request passes through centralized policy controls, guardrails, and full auditability, ensuring consistent governance across all model interactions.
Model Lifecycle Management
The platform supports the complete model lifecycle from building to tuning and scaling. In the build phase, developers hit one OpenAI-compatible endpoint to call any open or commercial model without GPU setup or cold starts. The tune phase enables supervised fine-tuning and LoRA adapter training on custom datasets, allowing organizations to adapt models to their specific language, data, and tasks. Evaluation gates measure quality and compare variants before production deployment, ensuring that model performance aligns with business requirements. All tuned models are automatically available through the same unified API endpoint.
Policy-as-Code and Governance
Tuning Engines implements a comprehensive governance framework through AGT YAML policies, which define access controls, guardrails, routing rules, and fallback behaviors as code. Administrators can configure role-based access controls with granular permissions, set per-key budgets and rate limits, establish routing profiles that direct requests to optimal models based on cost or latency requirements, and define fallback rules for failover scenarios. The platform provides full request traceability with runtime traces, usage analytics, and audit logs, enabling organizations to maintain compliance and security across all AI interactions.
Token Economics and Cost Controls
The platform implements sophisticated token economics with cost ceilings, quotas, routing optimization, and fallback strategies to keep spending and rate limits predictable. Infrastructure costs are passed through at-cost with zero markup, meaning organizations only pay for the actual compute consumed plus platform support fees. Administrators can set per-key budgets that automatically enforce spending limits, configure routing profiles that prioritize cost-effective models, and establish fallback rules that degrade gracefully when budget thresholds are reached. Billing controls and usage analytics provide full visibility into token consumption across teams, projects, and individual API keys.
Use Cases
Code Assistance and IDE Integration
Development teams can build and deploy AI-powered code assistants that integrate directly into popular IDEs and coding environments. Tuning Engines supports connections to Claude Code, OpenCode, Aider, Cline, Roo, Continue.dev, Cursor, VS Code, and Windsurf through a single governed platform. Developers get access to code generation, refactoring, debugging agents, and copilot functionality with centralized policy controls ensuring that all AI interactions comply with organizational security and governance requirements. The unified API allows seamless switching between models for different coding tasks, optimizing for speed, quality, or cost as needed.
Agentic Systems and Multi-Step Reasoning
Organizations can build and deploy agentic systems that perform multi-step reasoning, planning, and tool-using execution pipelines. The platform supports MCP servers, reusable skills, and agent definitions that can be governed through AGT YAML policies. Agents can access model catalogs, tool libraries, and skill repositories through the unified API, with full traceability and auditability across every step of the reasoning process. Centralized guardrails ensure agent behavior remains within defined boundaries, while routing and fallback policies maintain system reliability even when individual model calls fail.
Enterprise RAG and Knowledge Retrieval
Enterprises can deploy secure, scalable retrieval-augmented generation (RAG) systems over private knowledge bases and documents. Tuning Engines provides access to embedding models from the BGE and E5 families for semantic search, combined with language models for answer generation. The platform's governance layer ensures that all retrieved content is properly access-controlled, with role-based permissions and audit trails for every query. Centralized policy controls manage data capture, guardrails for content filtering, and cost tracking for token consumption across the entire RAG pipeline.
Multimodal Production Workflows
Teams can build and deploy multimodal AI systems that combine text, vision, and speech models in real-time production workflows. The platform supports vision models like Llama 3.2 Vision for image understanding and Whisper Large v3 for speech-to-text processing, all accessible through the same unified API. Organizations can route different modalities to specialized models based on task requirements, with fallback policies ensuring system resilience. Centralized governance applies consistent access controls, auditability, and cost management across all modalities, enabling complex multimodal applications like document processing, visual question answering, and voice-enabled assistants.
Frequently Asked Questions
How does Tuning Engines integrate with existing development workflows?
Tuning Engines provides an OpenAI-compatible API endpoint that works as a drop-in replacement for existing SDKs. Developers simply change the base URL from their current provider to "https://api.tuningengines.com/v1/" and use their Tuning Engines API key. All standard chat completion parameters, streaming, and structured output formats are supported. The platform also offers CLI workflows, MCP access, and direct integrations with major coding agents including Claude Code, OpenCode, Aider, Cline, Roo, Continue.dev, Cursor, VS Code, and Windsurf.
What models are available through the platform?
The model library includes open-weight models such as Llama 3.3 70B, Llama 3.1 8B, DeepSeek V3, DeepSeek R1, Qwen 2.5 72B, Qwen 2.5 Coder 32B, Mistral Small 3, Mixtral 8x7B, Gemma 2 27B, Llama 3.2 Vision, Whisper Large v3, and embedding models from the BGE and E5 families. Additionally, commercial frontier models are available, and any model fine-tuned through the platform is automatically accessible through the same unified endpoint. This provides access to over 100 models through a single API.
How does the pricing and cost model work?
Tuning Engines passes infrastructure costs through at-cost with zero markup. Organizations only pay for the actual compute consumed plus platform support and upkeep fees. Administrators can set per-key budgets, rate limits, and cost ceilings to control spending. Token economics features include cost-aware routing, fallback policies that optimize for cost, and detailed usage analytics for tracking consumption across teams and projects. Billing controls provide full visibility into spending patterns.
What governance and security controls are available?
The platform provides role-based access controls with granular permissions for users, teams, and API keys. Administrators can define AGT YAML policies for guardrails, routing rules, and fallback behaviors. Security features include credential sources management, full request traceability with runtime traces, audit logs for compliance, tenant isolation for multi-tenant deployments, and data capture controls. All API interactions pass through centralized policy enforcement, ensuring consistent governance across every model, agent, and tool.
Similar to Tuning Engines
Distro
Distro is an AI Distribution Operator that helps B2B teams publish content, find buyer conversations, engage prospects, and turn social intent into
Skygen AI
Skygen AI is an autonomous agent platform that executes complex multi-step tasks like data analysis, trip planning, and job applications directly.
HyperLake
HyperLake provisions sovereign AI agent infrastructure in your cloud with governed data access and zero compute markup.
Minded
Minded enables you to effortlessly create AI agents that handle tasks efficiently, training them through simple screen recordings and natural.

YCaaS
YCaaS delivers comprehensive AI agents that seamlessly manage all roles and processes from start to finish, enhancing operational efficiency.
xyOps
xyOps is a comprehensive workflow automation system for job scheduling, monitoring, and alerting, designed for scalable infrastructure management.
Editly AI
Editly AI is an automated video editing agent that transforms raw footage into polished content in minutes using simple text prompts, replacing.

Playwriter
Playwriter lets AI agents control your existing Chrome browser with full Playwright API access via a simple CLI.